Expressões Regulares - Um guia para iniciantes
12 de jan. de 2021Antes de aprender uma tecnologia é interessante entender que tipo de problema ela se propõe a resolver, então vamos lá… Imagine que você trabalha em uma aplicação que precisa receber o CPF com 11 dígitos numéricos. Qual seria sua abordagem para fazer uma validação? Acredito que caso não conheça regex, sua primeira opção seria verificar se o tamanho da string com os números digitados é 11, mas quem garante que tudo que foi passado são números?
"12345678909".lenght === 11; // Pode ser um CPF válido...
"123456789".lenght === 11; // Não seria um CPF válido...
"1234567890B".lenght === 11; // Aqui temos uma string com tamanho 9, mas é um CPF válido?
No código acima vimos 3 situações que provam que verificar apenas o tamanho da string não é garantia de que teremos um CPF válido, pois essa é uma verificação muito rasa que não garante que todos os caracteres passados são numéricos. Para conseguir ter a certeza de que os caracteres atendem aos requisitos que desejamos é preciso definir e verificar padrões e isso pode ser feito com uso de expressões regulares.
O que é uma expressão regular?
Em ciência da computação, uma expressão regular ou "Regex" (ou os estrangeirismos regex ou regexp) , abreviação do inglês regular expression) provê uma forma concisa e flexível de identificar cadeias de caracteres de interesse, como caracteres particulares, palavras ou padrões de caracteres. Expressões regulares são escritas numa linguagem formal que pode ser interpretada por um processador de expressão regular, um programa que serve um gerador de analisador sintático ou examina o texto e identifica as partes que casam com a especificação dada.
Diversas linguagens de programação tem sua própria implementação de expressões regulares, geralmente com pequenas diferenças e em alguns casos com diferenças bem significativas. Mas não se preocupe, pois, a base que você irá aprender a seguir vai ser de grande valor em qualquer linguagem de programação que você for se aventurar.
Agora você já sabe que uma expressão regular permite que palavras ou padrões de caracteres sejam encontrados em um texto, então vamos partir do exemplo mais básico que são os caracteres literais.
Antes de prosseguir recomendo que visite o site regex101 e vá reproduzindo os exemplos que forem sendo abordados ao longo do artigo.
Caracteres literais
Antes de prosseguir precisamos combinar que todas as nossas regex(expressões regulares) serão escritas entra duas barras(/SUA REGEX AQUI/). Agora que estamos na mesma página, qual seria a forma de encontrar todas as palavras "doce" que aparecem no nosso trava-línguas?
O doce perguntou pro doce\ Qual é o doce mais doce\ Que o doce de batata-doce.\ O doce respondeu pro doce\ Que o doce mais doce que\ O doce de batata-doce\ É o doce de doce de batata-doce.
Já que queremos encontrar a palavra "doce" vamos fazer um uso literal e nossa regex vai ficar assim: /doce/
PS: Tudo que for encontrado por nossa regex vai ser destacado com a cor azul.

Parabéns! Você acabou de fazer sua primeira regex, mas note que apenas a primeira palavra doce ficou azul… Isso acontece porque por padrão nossa expressão regular busca apenas a primeira ocorrência e para de procurar quando encontra algo que atenda o seu padrão. Tá, mas como resolvemos isso? Vamos resolver utilizando flags!
Flags
Flags são informações adicionais que passamos para mudar o comportamento da nossa regex. A estrutura de uma regex com flag seria assim: /doce/SUA FLAG
Existem diversos tipos de flags, mas por agora vamos focar apenas na g que significa global e indica que a busca só deve parar após encontrar todas as ocorrências do texto. Nossa regex ficaria assim /doce/g e esse seria o resultado das ocorrências:

Show de bola! Encontramos todas as ocorrências para a palavra doce, mas geralmente você não vai usar uma regex para buscar por uma palavra específica… O grande poder de uma regex é permitir que padrões sejam encontrados, então vamos "dificultar" um pouco mais as coisas. Preciso de uma expressão regular que seja capaz de encontrar todos os números do texto a seguir:
0 N4rut0 p0de 5er um p0uc0 dur0 às veze5, t4lvez v0cê nã0 s41b4 d1550, m4s 0 N4rut0 t4mbém cresceu sem p41. N4 verd4de ele nunc4 c0nheceu nenhum de seus p41s, e nunc4 teve nenhum 4m1g0 em n0ss4 4lde14. Mesm0 4ss1m eu nunc4 v1 ele ch0r4r, f1c4r z4ng4d0 0u se d4r p0r venc1d0, ele está sempre d1sp0st0 4 melh0r4r, ele quer ser respe1t4d0, é 0 s0nh0 dele e 0 N4rut0 d4r14 4 v1d4 p0r 1ss0 sem hes1t4r. Meu p4lp1te é que ele se c4ns0u de ch0r4r e dec1d1u f4zer 4lgum4 c01s4 4 respe1t0!
Para resolver esse problema precisamos aprender mais uma funcionalidade de expressões regulares.
Classes de caracteres ou conjunto de caracteres
Um conjunto de caracteres é uma lista de possíveis ocorrências que é passada entre []. No nosso caso queremos encontrar qualquer número no nosso texto, então podemos passar uma lista numérica da seguinte forma: [0123456789]\
É como se estivéssemos falando o seguinte para a nossa regex: eu quero que você encontre o digito 0, ou o digito 1, ou digito 2…
Outra forma de escrever um conjunto de caracteres é usando os intervalos. No nosso exemplo queremos encontrar os números de 0 até 9, logo podemos escrever um conjunto da seguinte forma: [0-9]. Se o objetivo fosse encontrar os números de 5 até 8 o conjunto seria [5-8].
Resumindo, nossa regex ficou assim/[0-9]/ e os números encontrados foram os seguintes:

A mesma lógica serve para conjuntos de letras ou de outros caracteres. Podemos usar uma sequência de letras assim [abcdefghijklmnopqrstuvwxyz] ou abreviar usando a sequência [a-z].
Um ponto de atenção!! A sequência de [a-z] é diferente de [A-Z]. A primeira vai encontrar apenas letras minusculas e a segunda apenas letras maiúsculas.
"Mas e se eu quiser encontrar as letras minusculas e maiúsculas?"
Vou te dar duas opções!
- Utilizando uma flag de case insensitivo(i) que seria assim
/[a-z]/i - Usando um conjunto com a sequência de letras minusculas ou a sequência de letras maiúsculas que seria assim
/[a-zA-Z]/
As duas opções vão reproduzir o resultado abaixo:

Se você analisar o resultado com cuidado vai ver que temos um pequeno problema… Não conseguimos encontrar todas as letras do nosso texto. Todas que possuem algum caractere especial(è,ã) foram ignoradas.
Classes de caracteres abreviados: o famoso shorthand
Ter que sempre escrever [0-9]ou [a-zA-z] seria um saco, mas felizmente existem maneiras de fazer as mesmas coisas escrevendo menos. Vou listar alguns das principais formas abreviadas
\dcorresponde a qualquer caractere numérico. O mesmo que[0-9]\Dcorresponde a tudo que não é um digito, incluindo caracteres especiais como!, ç~e etc.\scorresponde a espaços em branco, tabs, quebra de linhas.\Scorresponde a tudo que não for espaços em branco, tabs, quebras de linha.\wcorresponde a tudo que é alfanumérico. O mesmo que[a-zA-z0-9_]\Wcorresponde a tudo que não é alfanumérico. Pode ser utilizado em conjunto com \w para encontrar caracteres alfanuméricos e não alfanuméricos.[\w\W].é considerado um coringa, pois com ele podemos encontrar qualquer caractere, menos quebras de linha.
Quantificadores
Os quantificadores, também podem ser conhecidos como repetidores, dizem quantas vezes determinada ocorrência pode se repetir. Até o momento fizemos buscas por letras ou números, mas não chegamos a especificar quantas letras seguidas queremos encontrar, ou quantos números seguidos.
Pense na seguinte situação, precisamos encontra o número de uma placa de carro em um texto qualquer.

Uma placa de carro tem a seguinte estrutura: ABC-1234 (3 letras 1 hífen e 4 números). Note que apenas com o que aprendemos até agora é impossível encontrar o número da placa no texto abaixo:
O carro com a placa de número ABC-1234 foi furtado na manhã de domingo.
É ai que os quantificadores entram! Nós vamos dizer exatamente quantas vezes cada caractere vai se repetir para atender ao nosso padrão. Logo, nossa regex ficaria assim: /[a-zA-Z]{3}-\d{4}/g
A expressão regular é bem simples! Podemos separar ela em 3 partes para ficar mais fácil de entender:
[a-zA-Z]{3}Essa parte diz que qualquer coisa de a-z tem que aparecer 3 vezes-Aqui indica que é preciso ter um hífen\d{4}Essa parte diz que 4 números quaisquer devem aparecer seguidos.

Agora que você já tem uma ideia de como um quantificador pode ser usado, veja uma lista com outros quantificadores importantes:
{n}exatamentenrepetições/ocorrências.{n,m}no mínimonocorrências e no máximomocorrências.{n, }no mínimonocorrências e o limite máximo não existe.{, m}no máximomocorrências. Nesse caso o mínimo é 0.?0 ou 1 ocorrência; a mesma coisa que{, 1}+1 ou mais ocorrências; mesma coisa que{1, }*0 ou mais ocorrências.
Âncoras
Âncoras definem posições para que os caracteres sejam correspondidos. Uma âncora pode definir o início, o fim ou um limite para que o match seja feito. Vamos a seguinte situação: temos que encontrar arquivos que tenham um formato .gif. Pra que isso funcione precisamos garantir que o nome do arquivo sempre vai terminar com .gif. Nossa regex ficaria assim: /\w+.gif$/
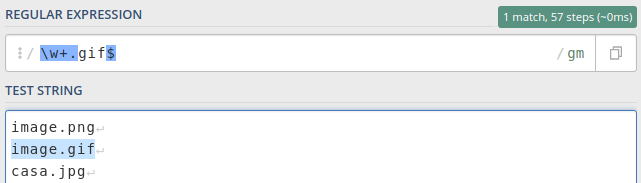
Explicando nossa regex…
\w+essa parte quer dizer para encontrar um ou mais letrar, números e underline..gif$essa parte quer dizer que a ocorrência deve terminar com.gif
Agora que você já tem uma ideia de como uma âncora pode ser usado, veja uma lista com outras âncoras importantes:
^inicio de um texto ou de uma linha, caso esteja utilizando a flag para multiline(m)\Ainicio de um texto$fim de um texto ou de uma linha, caso esteja utilizando a flag para multiline(m)\Zfim de um texto\bindica uma "borda" para a ocorrência, ou no inicio da palavra, ou no fim.
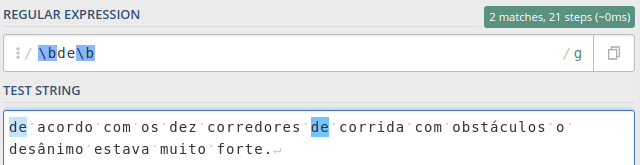
Um pequeno exemplo utilizando a âncora \b:
Nossa missão é encontrar todas às vezes que a preposição de aparece na frase abaixo.
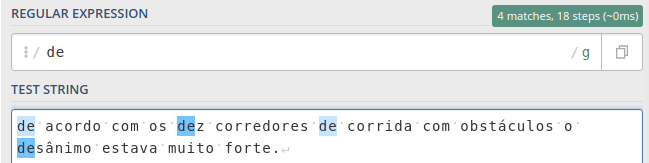
Note que com a expressão /de/ conseguimos pegar tudo que tem de, incluindo as palavras dez e desânimo. Uma solução é mudar nossa expressão para /\bde\b/.
Alternância
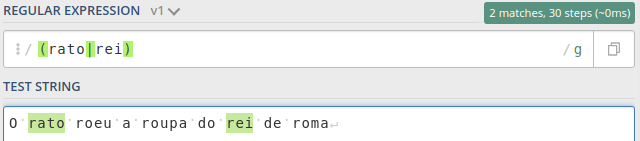
Esse é bem simples, pois existem casos onde queremos capturar uma ou outra ocorrência. Onde queremos encontrar o número 1 ou o número 2, a palavra rei ou a palavra rato. Pra isso só precisamos colocar que queremos encontrar entre parenteses e separar por uma |.
Vamos ao exemplo onde queremos encontrar as palavras rato e rei no texto abaixo. A expressão regular vai ficar assim: /(rato|rei)/
Isso é tudo pessoal!

Obrigado por chegar até aqui!! Espero que tenha conseguido te ajudar de alguma forma. 😊
Tudo que abordei até aqui é apenas o começo desse assunto tão vasto , mas acredito que seja o suficiente para que você dê um pontapé inicial e não fique tão perdido quando o assunto for expressões regulares. Recomendo dar uma conferida nos links que vou deixar mais abaixo, caso queira se aprofundar mais no assunto.