Entendendo renderização no browser: Como o DOM é gerado?
11 de out. de 2024Nos artigos anteriores nós aprendemos sobre o DOM e sobre o CSSOM, se você ainda tem dúvidas sobre essas duas palavrinhas recomendo fazer a leitura dos dois posts abaixo:
Recapitulando, o DOM é uma estrutura que o navegador utiliza para renderizar a nossa página. Porém, os dados da internet não são trafegados em forma de DOM, logo precisa existir um processo antes do DOM ficar pronto para o navegador consumir.
Nesse momento você pode estar se perguntando como os dados trafegam na internet?
Sempre que acessamos um site acontece uma troca em um padrão que chamamos de cliente x servidor.
Nessa troca o cliente (seu navegador) pede para acessar o site www.cristiano.dev para o servidor, que respondem com todo o conteúdo do site solicitado, mas esse conteúdo vem em forma de bytes e de uma forma que está distante do html/css/js que conhecemos.
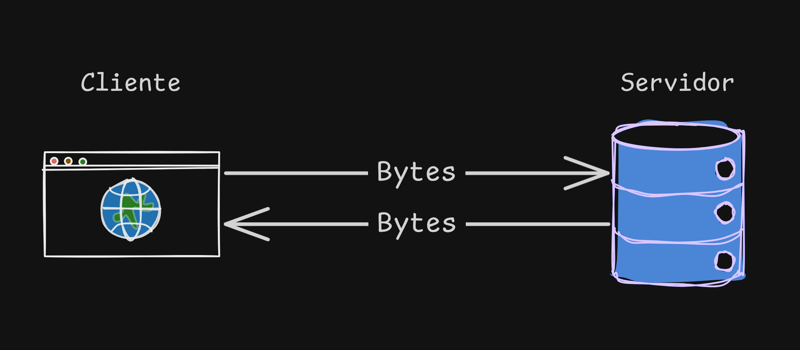
O que o browser vai receber do servidor é uma sequência de bytes.
Para esse pequeno trecho de html disponibilizado pelo servidor:
<!doctype html>
<html>
<head>
<title>Um título</title>
</head>
<body>
<a href="#">Um link</a>
<h1>Um cabeçalho</h1>
</body>
</html>
O navegador receberia em bytes mais ou menos assim:
3C21646F63747970652068746D6C3E0A3C68746D6C3E0A20203C686561643E0A202020203C7469746C653E556D2074C3AD74756C6F3C2F7469746C653E0A20203C2F686561643E0A20203C626F64793E0A202020203C6120687265663D2223223E556D206C696E6B3C2F613E0A202020203C68313E556D2063616265C3A7616C686F3C2F68313E0A20203C2F626F64793E0A3C2F68746D6C3E
Porém, o navegador não consegue renderizar uma página apenas com essa informação. Para que o nosso layout seja montado, o navegador vai executar alguns passos antes de ter o DOM.
Esses passo são:
- Conversão
- Tokenização
- Lexing
Conversão: Bytes para caracteres

Nessa etapa o navegador lê os dados brutos da rede ou de um disco e os converte para caracteres com base na codificação(encoding) especificada no arquivo, por exemplo, UTF-8.
Basicamente é a etapa em que o navegador transforma bytes para o código no formato que escrevemos no nosso dia a dia.
Tokenização: Caracteres para tokens

Nessa etapa o navegador converte strings de caracteres em pequenas unidades chamadas tokens. Todo início, final de tag e conteúdo são contabilizados, além disso, cada token possui um conjunto de regras específicos.
Por exemplo, a tag <a> possui atributos diferentes da tag <strong>
Sem essa etapa teremos apenas um monte de texto sem significado para o navegador e no fim desse processo o nosso html base seria tokenizado assim:
<!doctype html>➔ Token:DOCTYPE, Valor:html<html>➔ Token:StartTag, Nome:html<head>➔ Token:StartTag, Nome:head<title>➔ Token:StartTag, Nome:titleExemplo de título➔ Token:Character, Dados:Exemplo de título</title>➔ Token:EndTag, Nome:title<p>➔ Token:StartTag, Nome:pOlá, mundo!➔ Token:Character, Dados:Olá, mundo!</p>➔ Token:EndTag, Nome:p
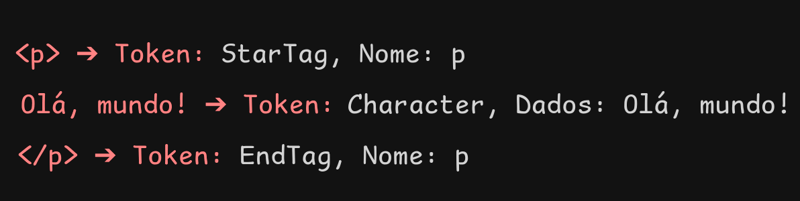
Um token é uma palavra ou símbolo individual em um texto. A "tokenização" é o processo de dividir um texto em palavras, frases ou símbolos menores.
Lexing: Tokens para nodes

A etapa de lexing(análise léxica) é responsável por converter os tokens em objetos, mas isso ainda não é o DOM. Nesse momento o navegador está gerando partes isoladas do DOM, onde cada tag será transformada em um objeto com atributos que tragam informações relacionadas a atributos, tags pai, tags filhas, etc.
O resultado após o lexing da nossa tag
seria algo assim:
{
"type": "Element",
"tagName": "p",
"attributes": [],
"children": [
{
"type": "Text",
"content": "Olá, mundo!"
}
]
}
Construção do DOM: Nodes para DOM
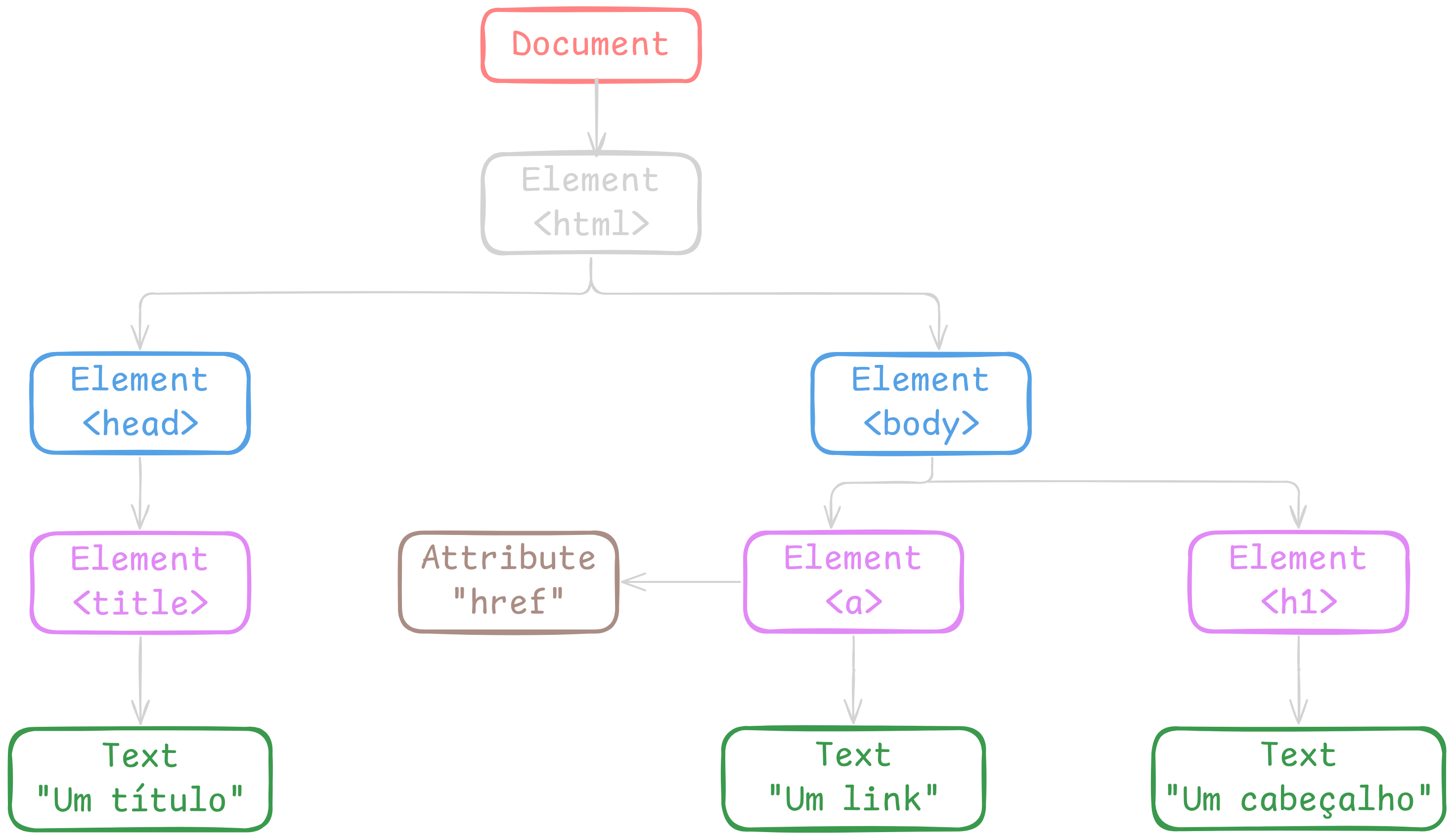
Finalmente chegamos na etapa de construção do DOM!
Nesse momento o navegador vai considerar as relações entre as tags html e vai juntar os nodes em uma estrutura de dados em árvore que represente essas relações de forma hierárquica. Por exemplo: o objeto html é pai do objeto body, o body é pai do objeto paragraph, até que toda a representação do documento seja criada.
Ao fim da construção o nosso html de exemplo se torna uma árvore de objetos como esta:
{
"type": "Document",
"children": [
{
"type": "Element",
"tagName": "html",
"children": [
{
"type": "Element",
"tagName": "head",
"children": [
{
"type": "Element",
"tagName": "title",
"children": [
{
"type": "Text",
"content": "Exemplo de título"
}
]
}
]
},
{
"type": "Element",
"tagName": "body",
"children": [
{
"type": "Element",
"tagName": "p",
"children": [
{
"type": "Text",
"content": "Olá, mundo!"
}
]
}
]
}
]
}
]
}
Recapitulando
O processo para construção do DOM é complexo e acontece nas seguintes etapas:
- Conversão: O html é recebido pelo navegador e convertido de bytes para caracteres.
- Tokenização: Os caracteres são transformados em tokens que representam as partes do html (tags, atributos, textos).
- Lexing: Os tokens são organizados em nós de objetos
- DOM: Os objetos são organizados em uma estrutura de dados do tipo árvore de forma hierárquica.
Para o CSSOM também acontece um processo semelhante, composto por conversão, tokenização e lexing.
Conclusão
Você deve estar se perguntando onde você vai aplicar esse conhecimento ao longo do seu dia a dia desenvolvendo…
É verdade que esse tipo de informação não vai ser requisitada com frequência, mas é importante entender como os navegadores, a principal ferramenta de trabalho de frontends, funcionam na sua essência.
Esse conhecimento também vai ser muito valioso para entender os próximos temas que iremos abordar por aqui: Paint, repaint, flow e reflow.
Muito obrigado!!
Obrigado por ter chegado até aqui!
Espero que tenha aprendido algo novo ao longo dessa leitura.
Até a próxima!